AI Conversation Intelligence in 2026: Why Sampling 5% of Sales Calls Is Costing You 22% of Revenue
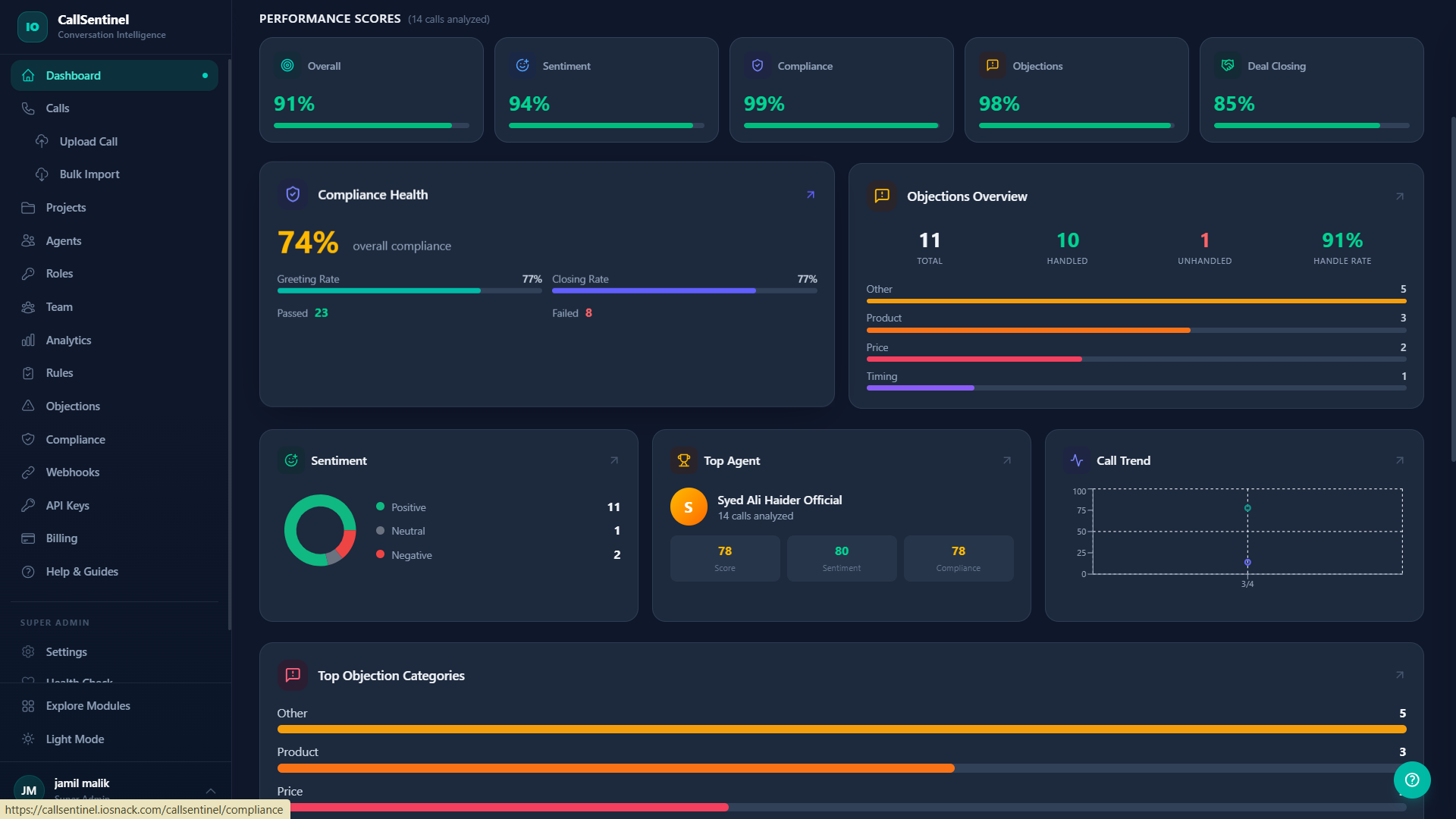
If you manage a sales or support team, here is an uncomfortable question. How many of your team's calls did you actually listen to last month? For most B2B teams, the honest answer is three to eight. Out of hundreds. Sometimes thousands. Then those same teams make six-figure decisions — coaching plans, script rewrites, performance reviews, even hiring and firing — based on that tiny, hand-picked sample. In 2026, this is the single most expensive habit B2B sales and support teams are still holding onto. This article walks through why the math no longer works, what AI-powered conversation intelligence actually does in production, and the real metrics from a recent 8-week deployment: 34% quality lift, 22% close-rate climb, and 60% less coaching time.
The Hidden Cost of 5% Sampling
Random call sampling is the QA equivalent of deciding what to plant on a 200-tree orchard by inspecting two trees and hoping the rest look the same. It feels rigorous because there is a process. It feels defensible because there is a spreadsheet. But the underlying math is brutal.
To get statistically reliable signal on a population of 500 monthly calls per rep, you would need to score roughly 60 random calls per rep per month. For a five-rep team, that is 300 calls. At 20-40 minutes per audit, that is 100 to 200 hours of QA work every month — the equivalent of a full-time analyst doing nothing else. No QA team listens to 60 calls per rep. So the math gets quietly relaxed to 5 random calls per rep — and decisions get made on noise.
The consequences are the kind that compound silently:
- Top performers look like luck. The thing they are actually doing differently never makes it into the random 5% the QA team listens to. So nobody learns from it.
- Compliance drift goes undetected for months. Three reps quietly missing the same disclosure line will not show up in a 5% sample reliably. A regulator might catch it before the QA team does.
- Script weaknesses cluster, not scatter. A weak late-funnel section killing 18% of deals will appear in maybe one in six calls. Sample-based QA will never flag a reliable pattern.
- Coaching becomes guesswork. Managers spend hours listening to randomly selected calls hoping to find a teachable moment, instead of being handed the exact 90-second clip that matters.
The honest takeaway: if you are sampling, you are guessing — and your team is paying for it in lost deals, missed coaching opportunities, and slow performance growth.
Why Traditional QA Approaches Break in 2026
Sample-based call audits are not broken because the auditors are bad. They are broken because three structural problems compound:
1. The Sample Size Doesn't Match the Decision
You are making decisions about a 500-call-per-month population using a 5-call sample. The confidence intervals on that sample are wide enough to drive a truck through. You cannot reliably say a rep got "better" or "worse" month-over-month with that little data — yet that exact comparison drives most performance reviews.
2. Human Scoring Drifts
Two human auditors will score the same call differently on a 1-10 quality rubric. Three weeks later, the same auditor will score the same call differently than they did the first time. So even the data you have is noisy. Layering trend analysis on top of noisy data produces beautiful charts that mean nothing.
3. The Cost of "Going Full Coverage" Was Always Prohibitive
To audit 100% of calls manually, you would need 3-4 full-time QA analysts for a 5-rep team. The headcount math has always killed this idea before it leaves the meeting room. Until AI conversation intelligence dropped the marginal cost of scoring a call to near zero — which is exactly what happened over the last 18 months.
What 100% AI-Scored Coverage Actually Looks Like
When every call gets transcribed, scored, and pattern-matched automatically, the QA function transforms from a random spot check into an always-on observability layer for your sales and support team. Five capabilities matter, in roughly this order of impact:
Custom Quality Rubrics on Every Call
Greeting, discovery questions, objection handling, closing, compliance — each scored against a rubric you define. Not generic call scoring. Your rubric, your weighting, your business. The dashboard updates within minutes of the call ending.
Sentiment and Intent Drift Detection
Where in the call did the buyer's tone shift? At minute 4 or minute 11? Was it during the price discussion or the timeline discussion? Sentiment-over-time graphs surface coaching moments you would never find by random sampling.
Compliance Auto-Flagging
Required disclosures, prohibited phrases, regulatory triggers — surfaced in real time, not after the audit cycle. Compliance teams move from quarterly fire drills to continuous monitoring with auditable trails.
Coaching Clips, Not Coaching Guesses
The system identifies the specific 90-second segment of a specific call where a rep needs intervention. Managers stop listening to random calls hoping for a teachable moment. They review pre-clipped, pre-tagged coaching moments with full context.
Pattern Detection Across the Team
When the same objection trips up four different reps, you see it in a dashboard, not a hunch. When one rep's opening style outperforms the team average by 30%, you can lift that pattern into a team-wide playbook in a week — not after six months of anecdotal observation.
"We discovered our top closer was not pitching harder. She was OPENING differently — and no one had noticed. Random sampling had missed it for two years."
Real Outcomes: An 8-Week Deployment
Last quarter, we deployed CallSentinel — our conversation intelligence platform — for a B2B sales team that was previously sampling about 4% of their calls. Here is the timeline of what changed.
Week 1 — The Uncomfortable Discoveries
Within the first week of 100% coverage, three patterns surfaced that two years of manual QA had missed entirely:
- The #1 closer was opening calls with a single qualifying question the rest of the team never asked. Once identified, it became a team-wide standard.
- Three reps were quietly missing the same regulatory disclosure line. Not because they were bad people — because the disclosure had been added to the script update six months earlier and never reinforced in coaching.
- A weak late-funnel script section was killing roughly 18% of late-stage deals. The pattern was invisible at 5% sampling because the weak section only came up in calls that reached late-funnel.
Weeks 2-4 — The Coaching Shift
Managers stopped scheduling generic "call review" sessions. Each rep now received 2-3 pre-clipped coaching moments per week, each tied to a specific rubric element with a specific recommended fix. Average coaching prep time per manager dropped from ~5 hours per week to ~2 hours per week. Coaching impact, measured by next-call quality scores, more than doubled.
Weeks 5-8 — The Compounding
By week 8, the metrics that matter had moved:
- Call quality scores lifted 34% across the team — not because reps got new skills, but because they finally knew which specific parts of the call to fix.
- Close rate climbed 22% — driven primarily by the script rewrite the data exposed, plus the opening-style standardization.
- Coaching time per rep dropped 60% — managers stopped listening to random calls and started reviewing pre-clipped coaching moments.
The lift did not come from hiring better people. It came from finally being able to see what was happening on every call.
How to Evaluate Conversation Intelligence Tools
If you are considering moving off sample-based QA, the market has gotten crowded. Most platforms now claim "AI-powered call analytics" — but the depth varies wildly. Look for these five non-negotiables when evaluating vendors:
1. Custom Scoring Rubrics
Your business is unique; your rubric should be too. Beware platforms that lock you into their pre-built scoring categories. You need to be able to define what "good greeting" means for your team — and adjust it as your motion evolves.
2. Multi-Language Transcription
If your team works across languages, English-only platforms force you back to sampling for non-English calls. In 2026, support for at least English plus your two primary languages should be table stakes. CallSentinel supports multiple languages out of the box, including Urdu, Arabic, and Hindi alongside English.
3. Function Calling and CRM Integration
Scoring without pushing data into your CRM is just dashboards. You want automation — auto-log the call outcome to Salesforce or HubSpot, auto-create a coaching task, auto-flag a compliance issue to the right team. Conversation intelligence without integration is half a product.
4. Sentiment and Intent Detection — Not Just Keywords
Keyword matching misses tone shifts and indirect objections. "Yeah, sure, sounds fine" can be enthusiasm or polite dismissal depending on tone and context. The right platform models intent and sentiment, not just transcript content.
5. Real-Time Coaching Alerts, Not Weekly Reports
The goal is faster intervention, not prettier slide decks. The right tool surfaces the coaching moment within hours of the call, not next Monday's pipeline review. CallSentinel sends coaching alerts to the right manager with the right clip, automatically — no human triage required.
What This Looks Like for Different Teams
The framework is the same; the application varies by team type:
- Outbound SDR teams: Focus on opening style, qualifying question quality, and objection handling. Expect the biggest lift in connect-to-meeting conversion.
- Account executive teams: Focus on discovery depth, late-funnel script execution, and close-question framing. Expect the biggest lift in close rate.
- Customer support teams: Focus on resolution rate, empathy markers, and compliance adherence. Expect the biggest lift in CSAT and first-call resolution.
- Call centers (BPO): Focus on script adherence, AHT optimization, and quality consistency across large rep populations. Expect the biggest lift in score variance reduction.
The Build vs Buy Decision
A reasonable question at this point: should you build this in-house or buy a platform? The honest answer depends on three factors.
Buy if your team is under 30 reps, your rubric is mostly standard sales/support patterns, and you want to be in production within 4 weeks. Off-the-shelf conversation intelligence will cover 80% of what you need, and the remaining 20% is rarely worth a custom build.
Build (or buy + customize) if your scoring needs are deeply industry-specific (heavily regulated industries, multi-language compliance, complex multi-product upsell flows), if you need to keep audio data inside your own infrastructure for compliance reasons, or if you want to integrate scoring directly with proprietary CRM logic. This is where a platform like CallSentinel — which we built from scratch and deploy on isolated infrastructure per client — earns its place over generic SaaS alternatives.
The Decision in Front of You
Every team that sells, supports, or services customers over the phone is making decisions about people, scripts, and quality based on incomplete information. Some teams are okay with that. They have decided 5% sampling is "good enough." The teams that are not okay with it are the ones lifting quality 34% and close rate 22% in two months — not because their reps got better, but because their visibility did.
The technology to score every call has gone from "$50,000/month enterprise project" to "weeks-of-deployment, transparent monthly cost" in roughly 18 months. The cost of not moving has stayed the same: the 95% of calls you are still ignoring, and the patterns hiding inside them.
If you would like to see what 100% AI-scored coverage looks like on your team's calls, we will run a free walkthrough of CallSentinel against a real or anonymized sample of your conversations. We will show you what we see, where the patterns hide, and what the lift would likely look like for your specific motion.
Stop sampling. Start seeing. Book a 30-minute walkthrough with our team, or explore the full CallSentinel module alongside our other 12 production SaaS modules.
Tags
Jamil Malik
Founder & Lead Engineer, IO Snack
A passionate technology professional at IO Snack, dedicated to helping businesses leverage technology for growth and innovation.